读论文系列·YOLO
CVPR2016: You Only Look Once:Unified, Real-Time Object Detection
转载请注明作者:梦里茶
 YOLO,You Only Look Once,摒弃了RCNN系列方法中的region proposal步骤,将detection问题转为一个回归问题
YOLO,You Only Look Once,摒弃了RCNN系列方法中的region proposal步骤,将detection问题转为一个回归问题
网络结构
- 输入图片:resize到448x448
- 整张图片输入卷积神经网络(24层卷积+2层全连接,下面这张示意图是Fast YOLO的)

- 将图片划分为个格子,
- 输出一个大小的class probability map,为图片上每个格子所属的分类
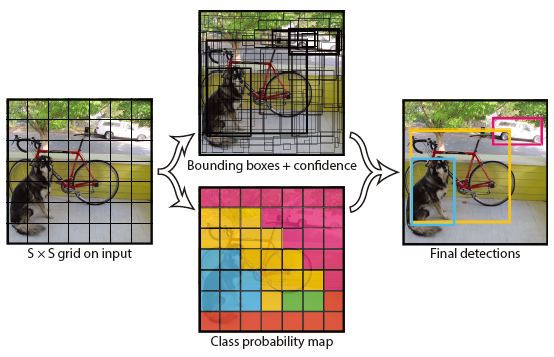
- 输出为每个格子输出B个bounding box,每个bounding box由x,y,w,h表示,为每个bounding box输出一个confidence,即属于前景的置信度
于是输出可以表示为一个的tensor,训练只需要根据数据集准备好这样的tensor进行regression就行
- 对所有bounding box按照confidence做非极大抑制,得到检测结果
训练
Loss
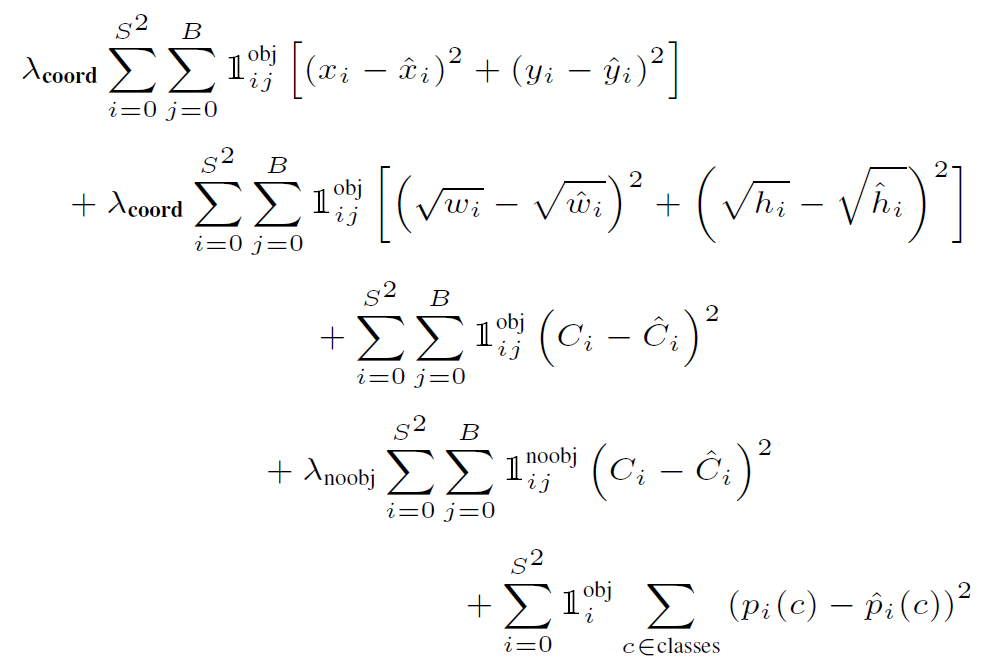
- 前两行为定位loss,为定位loss的权重,论文中取5
- 第三行为一个bounding box属于前景时的置信度回归loss,
- 当格子中有对象出现时,真实为1,
- 是一个条件表达式,当bounding box“负责(is responsible for)”图中一个真实对象时为1,否则为0,
- 所谓“负责”,指的是在当前这个格子前向传播(论文里没讲,有代码依据)预测出的所有bounding box中,这个bounding box与真实的bounding box重叠率最大
- 第四行为一个bounding box属于背景时的置信度回归loss,
- 为了避免负样本过多导致模型跑偏, ,
- 是一个条件表达式,为取反
- 于是我们可以发现一个格子的两个bounding box的分工:一个贡献前景loss,一个贡献背景loss ,不论是前景背景box,我们都希望它们的confidence接近真实confidence,实际上,如果 , 第四五行可以合并为一项求和,但由于背景box太多,所以才单独拆开加了权重约束
- 第五行为分类loss,是一个条件表达式,当有对象出现在这个格子中,取1,否则取0
YOLO里最核心的东西就讲完了,其实可以把YOLO看作固定region proposal的Faster RCNN,于是可以省掉Faster RCNN里region proposal部分,分类和bounding box regression跟Faster RCNN是差不多的
细节
Leaky Relu
网络中只有最后的全连接层用了线性的激活函数,其他层用了leaky Relu:
对比Relu和leaky Relu
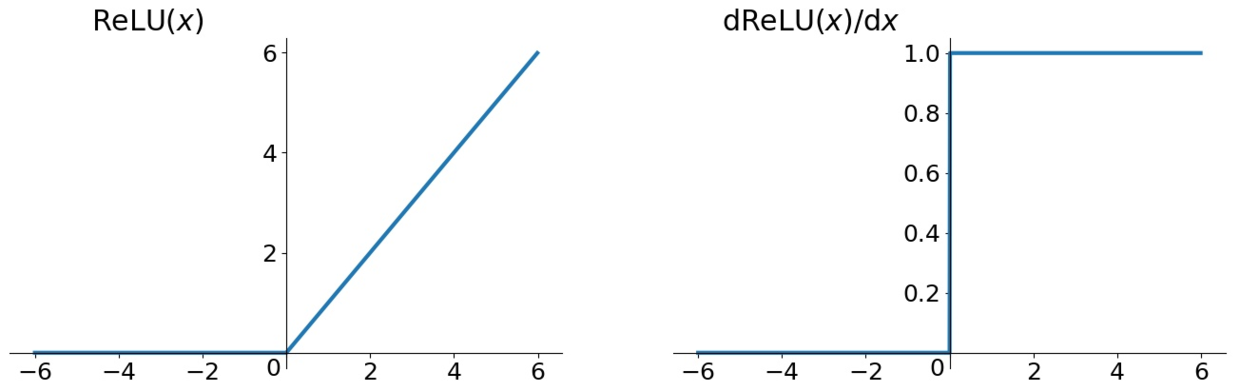
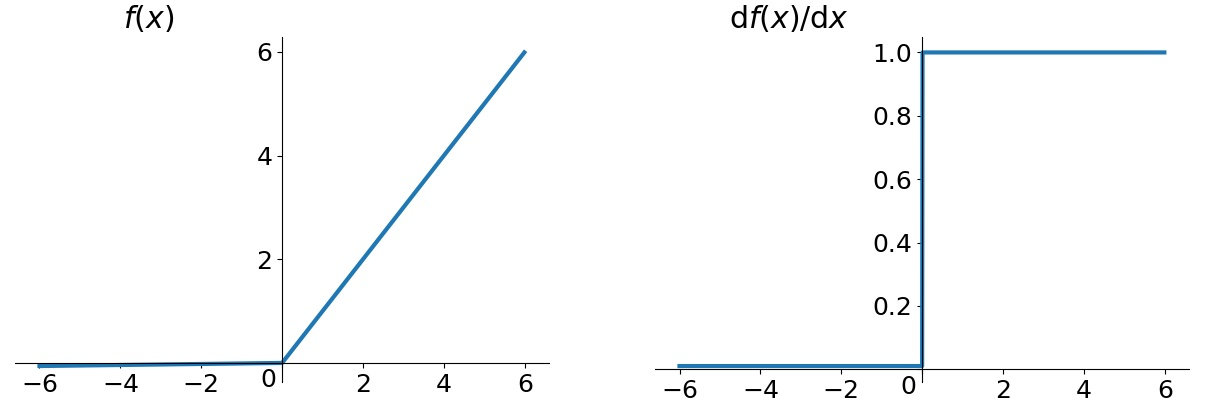 在x小于0的时候,用了0.1x,避免使用relu的时候有些单元永远得不到激活(Dead ReLU Problem)
在x小于0的时候,用了0.1x,避免使用relu的时候有些单元永远得不到激活(Dead ReLU Problem)
Fast YOLO
卷积层更少,只有9层卷积+2层全连接,每层filters也更少,于是速度更快
实验效果
- 对比当前最好方法:
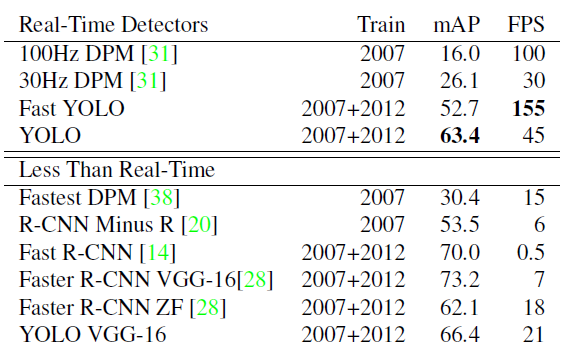 Fast YOLO速度最快,准确率不太高,但还是比传统方法好,YOLO则比较中庸,速度不慢,准确率也不太高,但也还行。
Fast YOLO速度最快,准确率不太高,但还是比传统方法好,YOLO则比较中庸,速度不慢,准确率也不太高,但也还行。
- 再看看具体是在哪些类型的图片上出错的:
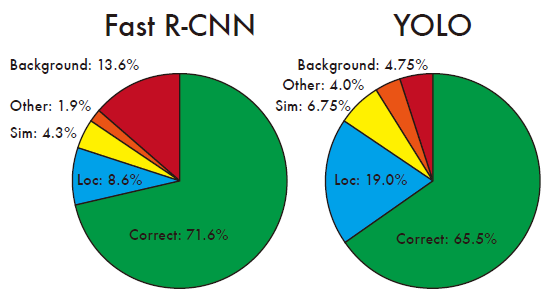 主要是定位不准(毕竟没有精细的region proposal),但是在背景上出错较少(不容易把背景当成对象)
主要是定位不准(毕竟没有精细的region proposal),但是在背景上出错较少(不容易把背景当成对象)
缺点
- 固定的格子是一种很强的空间限制,7x7的格子决定了整张图片最多预测98个对象,对于对象数量很多的图片(比如鸟群)无能为力
- 难以泛化到其他形状或角度的物体上
- 损失函数没有考虑不同尺寸物体的error权重,大box权重和小box权重一样
Summary
Anyway,YOLO结构还是挺优雅的,比Faster RCNN黑科技少多了,更重要的是,它是当时最快的深度学习检测模型,也是很值得肯定的。